MemryX Architecture: Introduction
An introduction to the MemryX tower architecture
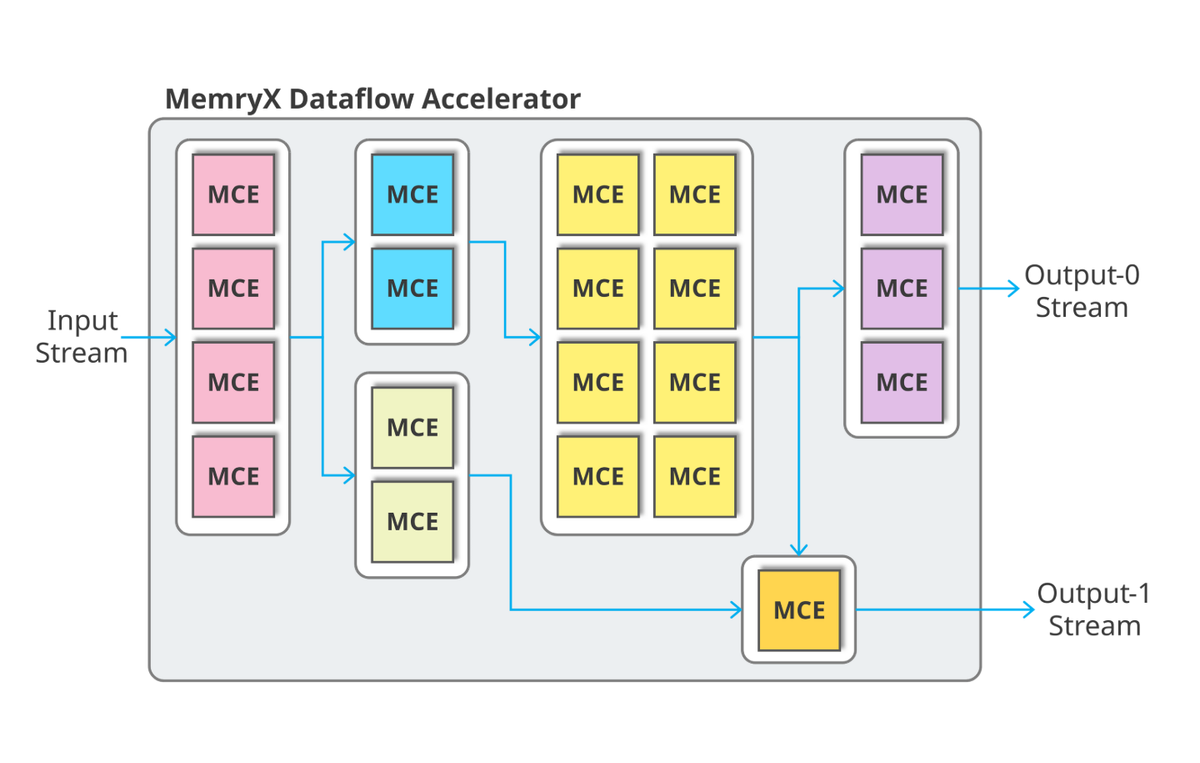
The MemryX tower architecture is a streaming, many-core, near-memory dataflow design created from the ground up to accelerate AI workloads such as neural networks. In this post, we’ll introduce the key ideas behind the architecture—why each feature exists, and how it impacts overall performance and efficiency.
What we’ll cover in this intro post:
- Why dataflow
- The main building blocks (Dataflow cores + distributed memory)
- How the “tower” organization supports streaming execution
- A quick look at the compiler’s role
The full whitepaper on MemryX's architecture is always available on the DevHub as well!
Why Dataflow
Neural networks are naturally expressed as compute graphs. Rather than relying on traditional control-flow architectures, we use a Dataflow compute paradigm that natively aligns with these graphs.
In control-flow style architectures, a considerable amount of time and hardware resources are devoted to decoding instructions, computing addresses, and pre-fetching data. Data movement is inherently energy inefficient, and transistor area is better spent on compute and storage than on-chip control-flow.
Additionally, data routing and workload scheduling must be carefully managed to achieve any meaningful utilization of the hardware, resulting in a more complex software stack that often needs to be optimized on a per-model basis.
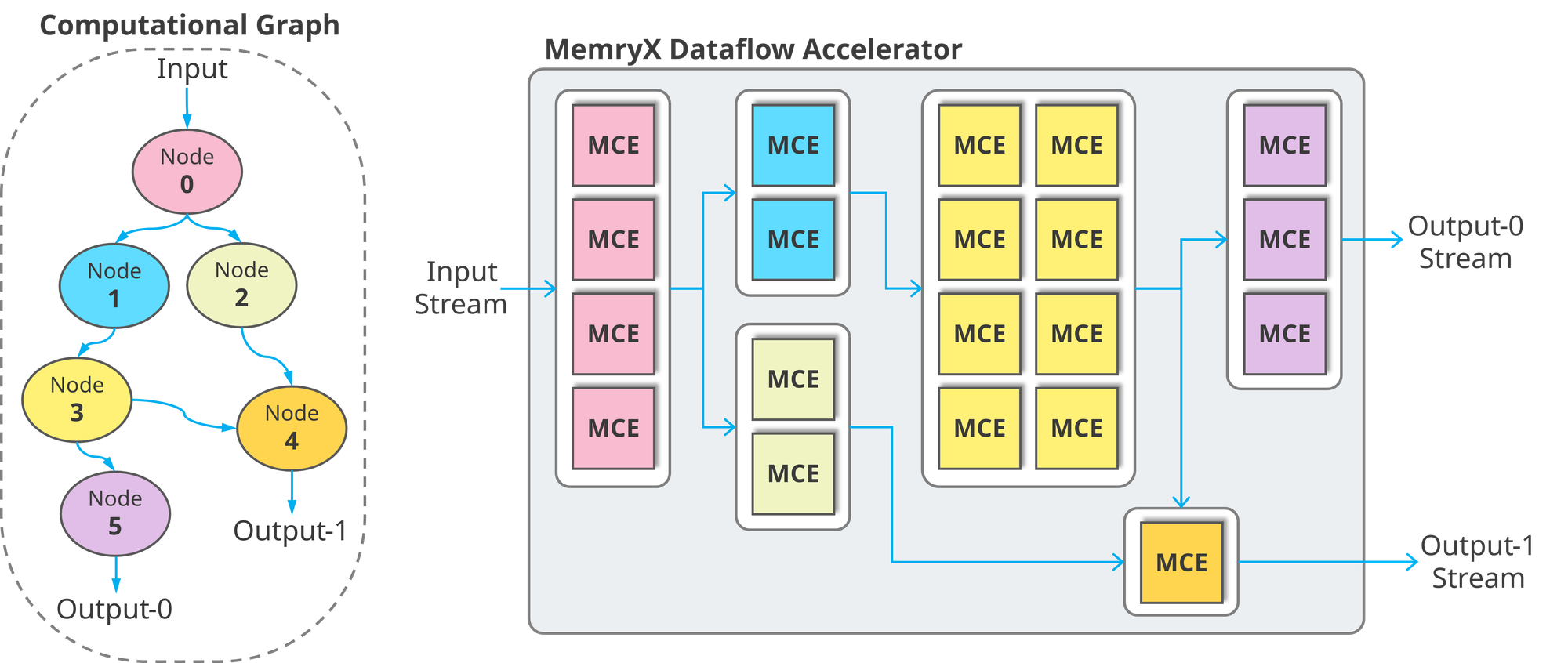
Many-Core, Data-Driven Execution
MemryX Tower architecture consists of numerous heterogeneous dataflow cores—called MemryX Compute Engines (MCEs)—operating independently in a fully data-driven manner. Control is decentralized, enabling each MCE to process data as soon as it becomes available.
The MX3 contains two main types of MCEs: MAC cores (M-Cores) and ALU cores (A-Cores). By dividing the workload among multiple cores, the MemryX architecture naturally supports space multiplexing, allowing each neural network layer to be mapped efficiently and streamed through the dataflow pipeline.
MemryX modular dataflow architecture enables different types of MCEs to be implemented in future chips while maintaining necessary compatibility.
Distributed On-Chip Memory
On-chip distributed memories play a central role. Two key and separate memory types are used: weight memories that store neural network parameters, and feature-map memories that hold input, output, and intermediate data during inference.
The feature-map memory also acts as the communication medium between processing elements, eliminating the need for a centralized on-chip memory and enabling software-defined data pathways. Each core or cluster of cores writes its partial results to the feature-map memory, allowing consumer clusters to read from this same shared buffer.
This seamless data exchange reduces complexity by avoiding direct core-to-core communication and offers robust scaling options for larger systems and more complex models.
The “Tower” Organization
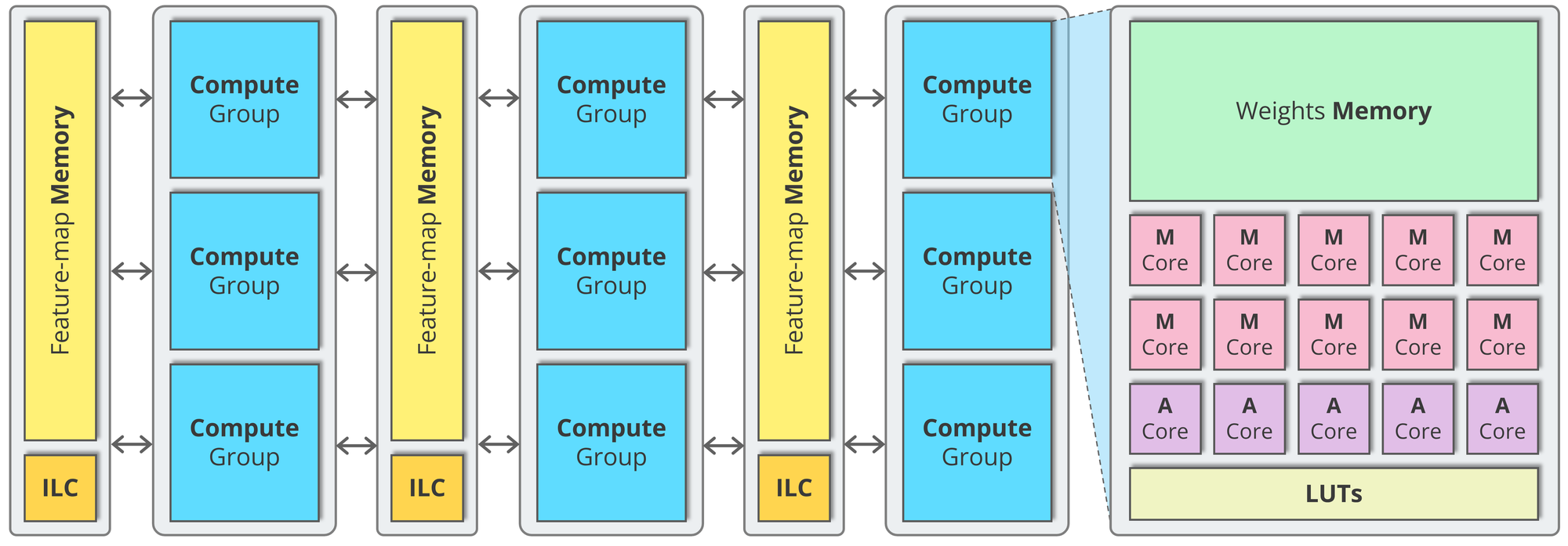
Cores and memories can be arranged in interleaving stacks that give rise to the “tower” nomenclature, as shown in the next figure.
Each compute tower contains an optimized number of groups of M-Cores and A-Cores alongside local weight memory, interleaved with feature-map towers. Every M-Core interfaces with local weight memory, adjacent feature-map towers, and neighboring M-Cores. A-Cores similarly interface with local LUTs (lookup tables) and adjacent feature-map towers.
This arrangement is optimized for efficient dataflow execution, as neural network inputs stream through multiple layers until reaching the final output.
Compiler-Driven Streaming Execution
The MemryX compiler programs the architecture offline and leverages a streaming execution model. Cores or clusters of cores are assigned specific tasks, processing incoming data and passing results forward in a pipeline.
The compiler predetermines both how each core is programmed and how data flows between cores, ensuring balanced workload distribution and data coherence. One key objective is to maintain or create close producer-consumer relationships, strategically placing related operations near each other to maximize efficiency and minimize data movement.
What’s Next
In the posts that follow, we’ll highlight how the architecture’s features come together to enable efficient, scalable, and accurate acceleration of neural networks on MemryX hardware.