Our Model eXplorer Is Not a Zoo
A lot of AI accelerators look great on benchmark charts—until you try to run your model.

Why? Because many platforms rely on shortcuts (like 8-bit activation quantization) to hit peak throughput. That can be a valid engineering choice, but it often comes with a real cost for developers: calibration runs, pilot datasets, per-model tuning, accuracy tradeoffs, and sometimes retraining. When “good performance” requires that much per-model effort, vendors often end up maintaining a curated model zoo to keep the experience smooth (at least as long as you stay inside the zoo).
Step outside that curated list and reality hits. Performance can drop sharply. Extra steps appear (calibration, retraining, custom toolchains). In some cases, portability becomes painfully limited.
Zoo-free by design
MemryX accelerators were built from day one for ease of use without sacrificing performance. The goal is simple: developers should be able to bring already-trained models and deploy them without needing a special workflow.
Take activation quantization as an example. At MemryX, we introduced a concept we call Group-Bfloat, which is designed to provide the dynamic range AI models need while delivering performance close to 8-bit quantization. We also have many other innovations that can make MemryX even faster than INT8-based approaches, but we’ll save those details for future posts.
Model eXplorer is our proof—at scale
Because MemryX can achieve strong performance and accuracy out of the box, there’s no need for a curated model zoo. Instead, we built the MemryX Model eXplorer to show what “out-of-the-box” really looks like.
Behind the scenes, an automated system discovers publicly available models online, compiles each one into a MemryX DFP (dataflow program), and runs it on MemryX hardware. The model remains intact through this process (no pruning, optimization, or retraining required to maintain accuracy). The same automation publishes the results to Model eXplorer, filtering to models from trustworthy public sources. The hundreds of models you see aren’t hand curated for a narrow showcase—they’re compiled as they were trained, directly from their source.
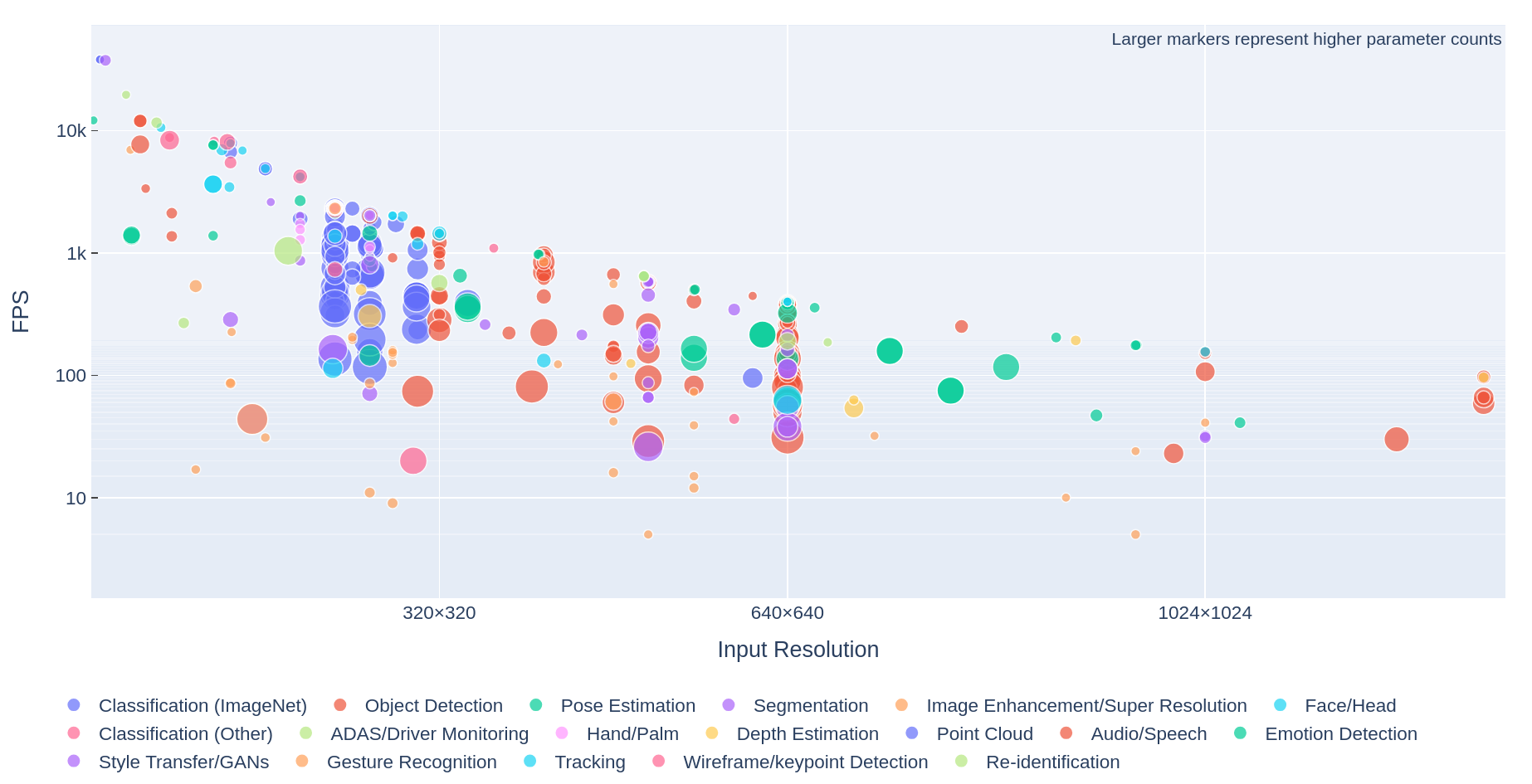
That’s why Model eXplorer spans so many categories, and why each SDK release continues to expand coverage and improve performance. The outcome is simple: more real-world models running out of the box on MemryX, with less friction and fewer steps.

“But what if I want to prune or optimize?”
Absolutely—you can. If you’re willing to trade accuracy for performance (or invest extra effort for peak performance), you can prune, quantize, distill, and so on—then compile and measure as usual. The key difference is: it’s optional, not a prerequisite.