SDK 2.2 Coming Soon!
Our biggest release since 2.0

It's been a while since SDK 2.1 was released, but for good reason: we've packed the upcoming SDK 2.2 with tons of new features and optimizations.
We'll highlight some of the most important ones below, and the full release notes will be published along with the stable release, which will be available to the public Very Soon™.
YOLO v10, 11, and 26 Boosts
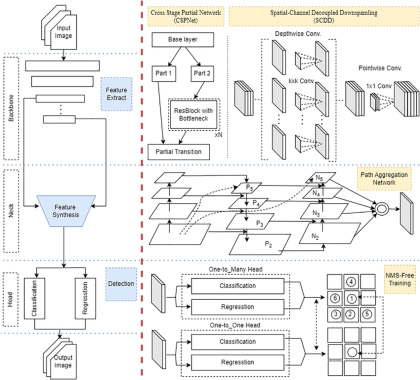
The partial self-attention blocks introduced by YOLO v10, while supported, were relatively slow on MX3 with SDK 2.1 and earlier. YOLO11 and 26 are essentially rebranded v10 models, so this applied to them too. So we introduced MXA-optimized YOLO11 to show how simple modifications to the models could yield massive FPS gains on MX3.
However with SDK 2.2, we've "cracked the code" and now have a much faster mapping of these attention blocks to the MX3's instruction set (if you can really call it that).
With this Compiler change, some of the affected models have over 400% more FPS, bringing them up to par with the MXA-optimized versions without any modifications to the model. A few models such as YOLO11-nano-640 have healthy boosts to FPS, yet the MXA-optimized version is still faster, so we are leaving both versions on the Model Explorer for these cases.
Compiler Optimizations
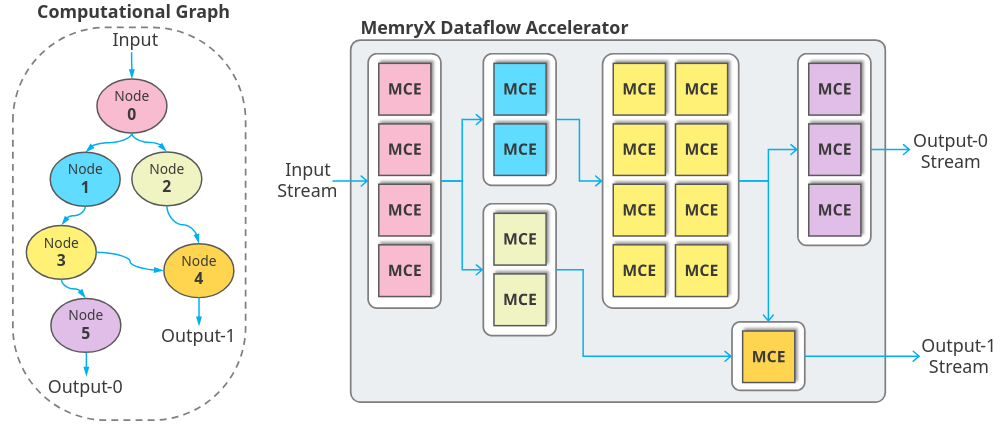
New mapping techniques and optimizations in the Neural Compiler in SDK 2.2 benefit not only YOLO models though.
The Compiler has refined its strategy for mapping layers to A-Cores, which yields improvements to models across many different categories. Over 130 models on Model Explorer gained 5% or more FPS from SDK 2.2!
MxPrepost
Speaking of YOLO models, a common pain point when making an app for MXA has been the cropped pre/post sections created by --autocrop. While our runtime APIs offer automatic execution of these crops, the onnxruntime / tflite sessions we use can incur significant CPU load, especially on ARM devices. That's why some of our examples implement these crops, which just manipulate some data around, directly in numpy to improve performance and lessen CPU load.
So with SDK 2.2, we've packaged this optimized code and created a new library we're calling MxPrepost (dead link until 2.2 is released).
This library removes the overhead of onnxruntime with an easy-to-use .preprocess and .postprocess API, for:
- YOLO v7, v8, v9, v10, and 11 models
- Including custom models with any number of classes or input resolution
- Object detection, pose estimation, and instance segmentation tasks
- Python and C++
A few examples have been rewritten to use MxPrepost, and more will be updated over time, while others retain the old onnxruntime pre/post crop method as a reference for non-YOLO application developers.
MxPrepost's release cadence is separate from the overall SDK, so expect to see frequent updates for bugfixes and YOLO26 support.
Driver DMA Optimizations
Though the driver isn't the most user-visible SDK component, it is critical to performance and stability. With 2.2, we've reworked how data is transferred to and from the MX3, raising the effective PCIe bandwidth cap.
This will benefit models where the transfer between host and MX3 was the bottleneck, not the MX3's inference performance itself. For example, 640x640 resolution YOLO object detectors used to be limited to around 380 FPS. With SDK 2.2's driver + firmware, these models can reach 420 FPS. This is with the same DFP, making this ~10% gain totally "free".
Python-wrapped MxAccl API
Up until now, we have maintained two separate runtime APIs: C++ (MxAccl) and Python (SyncAccl, AsyncAccl, MultiStreamAsyncAccl). Not only has this been a maintenance burden, but the pure Python implementation naturally incurs a performance drop vs. C++.
So in SDK 2.2, we've used pybind11 to create a Python interface to our underlying C++ runtime, which we call Python-wrapped MxAccl for now – later, we'll have just one API page with 'Python' and 'C++' tabs.
This "new" API boosts performance for Python apps, especially when multiple streams are involved.
New Model Explorer Sources
Through a combination of Compiler improvements and additional sources for our Model Explorer script to pull from, we have benchmarked and published results for 115 new open-source models!
If you haven't already, read about our approach to model support here, where we talk about how all published numbers are on original, unmodified, not-retrained, not-quantized models – something unique in the AI accelerator field where most people "cheese" benchmarks with model modifications and retraining.
So, When 2.2?
Things can always come up at the last moment, so we won't commit to an exact date, but we can say that things are on track for a release in about 1 week 🎉
We hope you'll enjoy the new SDK, and always feel free to reach out to us on the community forum with questions or thoughts!